
생산 스케줄링에 의한 기계의 효율적인 배치
저희 공정에서는 설비가 수백 대 있습니다. 같은 설비가 몇 대씩 있기도 하고, 사양이 조금 다른 설비도 혼재 하고 있습니다. 생산 스케줄링은 수작업으로 하고 있고, 설비에로의 할당은 고정적으로 정해서 하고 있읍니다. 고정적으로 정해 버리는 스케줄링에서는, 대체 설비가 비어 있음에도 불구하고 작업이 진행 되지 못해 비 효율적입니다. 설비에로의 할당을 효율적으로 실현 할 수 있는 생산스케줄링 방법을 알려 주십시오.
데이터를 정리해, 생산스케줄링을 활용하자
일반적으로는, 제품별・공정 별로 작업을 담당 할 수 있는 설비와 라인이 복수 존재하고, 각 설비에 따라 작업 스피드가 달라 진다.
이것을 앞에서도 등장한 유한 능력 스케줄링( FCS : Finite Capacity Scheduling) 시스템을 사용해, 질문 하신 내용을 스케줄링 해 본다.
생산스케줄링을 위한 마스터 데이터를 등록해 (그림1),
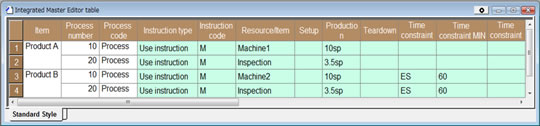 그림1생산스케줄링을 위한 마스터 등록, ( 공정1이 설비1에서 만 가공 가능한 설정). 제품A는 공정1, 공정2를 통과해 생산된다. 공정1은 설비1에서만 가공 할 수 있고, 1개당 10초의 처리 시간이 걸린다. (능력 값 = 10sp : Second per piece). 공정2는 검사 공정으로 1개당 3.5초의 처리 시간이 소요된다. 그림1생산스케줄링을 위한 마스터 등록, ( 공정1이 설비1에서 만 가공 가능한 설정). 제품A는 공정1, 공정2를 통과해 생산된다. 공정1은 설비1에서만 가공 할 수 있고, 1개당 10초의 처리 시간이 걸린다. (능력 값 = 10sp : Second per piece). 공정2는 검사 공정으로 1개당 3.5초의 처리 시간이 소요된다. |
복수 제조 오더(그림2)
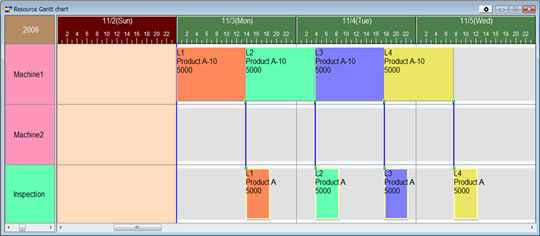 그림2 생산스케줄링을 위한 오더 등록. 전부 4개의 오더 ( L1 , L2 , L3 , L4)를 등록 했다. 오더 L1은, 제품A를 11월 10일 까지 5000개 만든다. 그림2 생산스케줄링을 위한 오더 등록. 전부 4개의 오더 ( L1 , L2 , L3 , L4)를 등록 했다. 오더 L1은, 제품A를 11월 10일 까지 5000개 만든다.
|
를 투입해 생산 스케줄링을 하면 사용하는 설비에 치중된 결과가 된다(그림3).
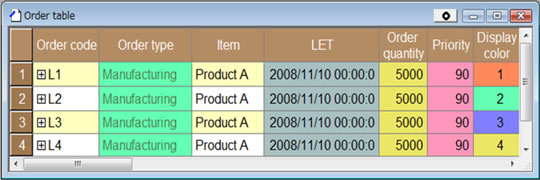 그림3 생산스케줄링 결과, 대체 설비를 사용 하지 않는 경우. 공정1이 설비1에 모두 할당되어 버리므로, 설비2에서 제품A가 가공 가능 한데도 설비2에는 할당 되지 않는다. 이 그림3 생산스케줄링 결과, 대체 설비를 사용 하지 않는 경우. 공정1이 설비1에 모두 할당되어 버리므로, 설비2에서 제품A가 가공 가능 한데도 설비2에는 할당 되지 않는다. 이 |
공정1의 대체 설비가 설비2라 하면, 설비2가 유효 활용되고 있는 생산 스케줄링 결과라고는 말 할 수 없다.
생산스케줄링을 위한 등록 오더 량이 적다면, 사람이 생각해도 공정1의 몇 가지 작업 (그림3에 있어서 바) 을 설비2 쪽으로 이동 하면 된다고 바로 알 수 있다. 그러나, 설비 수가 수백 대, 작업수가 수천, 수만 이 넘거나, 담당 할 수 있는 품목과 설비의 조합이 복잡한 관계를 가진 다면, 사람이 하는 이들 관계를 고려해 생산 스케줄링을 짜게 되는 것은 상상 만 해도 어려운 복잡한 작업이 된다.
여기서, 자동적으로 공정1의 작업을 설비2에도 할당 하도록 마스터 데이터를 변경해 (그림4),
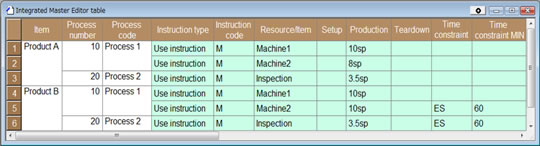 그림 4 대체 자원의 등록. 제품A의 공정1이 설비1 만으로 처리 하는 것이 아니라, 설비2에서도 처리 할 수 있다. 능력 치는 8sp 이다. 그림 4 대체 자원의 등록. 제품A의 공정1이 설비1 만으로 처리 하는 것이 아니라, 설비2에서도 처리 할 수 있다. 능력 치는 8sp 이다.
|
생산스케줄링 한다. 결과는 각 설비의 부하가 평준화 되어, 관성 일시가 빨라지게 된다 (그림 5)。
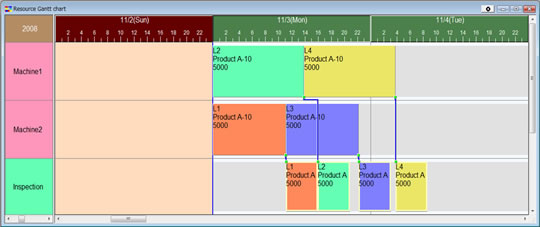 그림 5 생산스케줄링 결과 공정1의 작업을 설비2(대체 자원)에 자동적으로 스케줄링하는 경우. 오더L1과 L3은 자동적으로 설비2에 이동된다. 설비2는 보다 고속이므로 바의 길이도 짧아 진다. 오더L4의 완성은 11월 6일의 낮 경이 된다. 이것은, 그림3의 결과 보다 하루 빠르게 되어 있다. 이 스케줄링에서는 공정1에 있어서 설비1과 설비2으 의 부하를 평준화 하도록 계획 작성 파라미터를 지정하고 있다. 그림 5 생산스케줄링 결과 공정1의 작업을 설비2(대체 자원)에 자동적으로 스케줄링하는 경우. 오더L1과 L3은 자동적으로 설비2에 이동된다. 설비2는 보다 고속이므로 바의 길이도 짧아 진다. 오더L4의 완성은 11월 6일의 낮 경이 된다. 이것은, 그림3의 결과 보다 하루 빠르게 되어 있다. 이 스케줄링에서는 공정1에 있어서 설비1과 설비2으 의 부하를 평준화 하도록 계획 작성 파라미터를 지정하고 있다. |
실제 공장에서는 생산스케줄링을 위해 등록해야 할 데이터 량이 방대하므로, 데이터의 등록작업은 상당한 노력이 필요하다. 예를들면, 귀사의 공장에는 제품이 1000품목 있고, 작업 공정이 평균 약 10공정이라면, 1000×10=10000행의 데이터를 등록해야만 한다.
생산스케줄링을 위한 데이터의 정리는 상당히 어려운 작업이지만, 그 결과로 나온 데이터의 가치는 아주 크고 귀중하다.
작업시간과 작업 준비 시간이 생산스케줄링 담당자의 머리 속에만 있어서는, 그 생산스케줄링 담당자가 장기 입원한다든지 정년 퇴직 하는 경우에는 리스크가 아주 크게 된다. 귀사에서도 데이터의 정리를 첫 스텝으로, 유한 능력 (생산스케줄링)의 사고 방법을 도입 하기를 추천 한다.